



Forecasting Mental Health Hospital Bed Occupancy: A Regime-Switching AutoRegressive Hidden Markov Model Approach
Mustafa Aslan, Cardiff University, UK
Lead supervisor: Prof. Bahman Rostami-Tabar
Co-supervisor: Dr. Jeremy Dixon
Data Lab for Social Good
Cardiff University, UK
16 Sep 2025
Current Systemic Issues in Patient Flow

- Unpredictable occupancy levels can result in redundant staffing and resource allocation, driving up costs, or in understaffing, which compromises patient care.
- Spikes in occupancy level drive overtime, sickness, and staff burnout.
- Lack of analytical solutions that can capture the complexity and uncertainty of patient flow and bed availability limits proactive decision-making.
Why is it important?
Why is an efficient bed management system crucial?
- Hospital beds are one of most costly healthcare resources.
- NHS rates for acute mental health beds are generally between £760 and £850 per day in 2025
- Bed shortages force some patients to wait in corridors, impacting care quality and safety.
- Bed shortages increase staff pressure, burnout, and operational costs.

Why a reliable forecasting approach is needed?
- Mental health demand is volatile and influenced by unpredictable crisis, by seasonality, epidemics, and unforeseen events.
- A reliable forecasting approach enables timely staffing, resource allocation, and improved patient care.
- Anticipating demand allows decision-makers to balance scarce resources while improving patient flow and safety.
- Robust forecasts enhance resilience to unexpected surges and reduce staff burnout.
Data characteristics
Strong upward trend in occupancy over time
Spike after COVID-19 pandemic
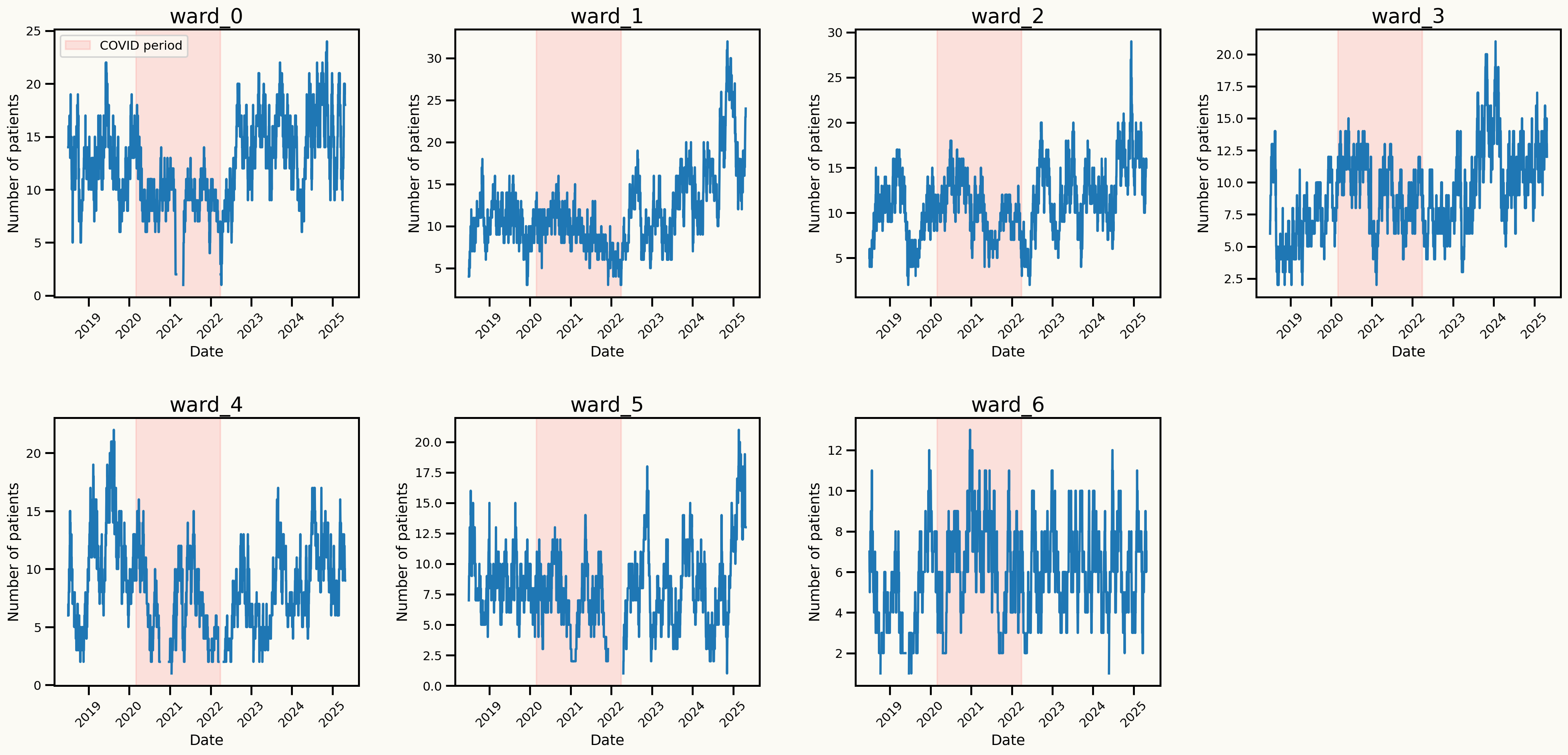
Seasonal patterns
Day of the week seasonality
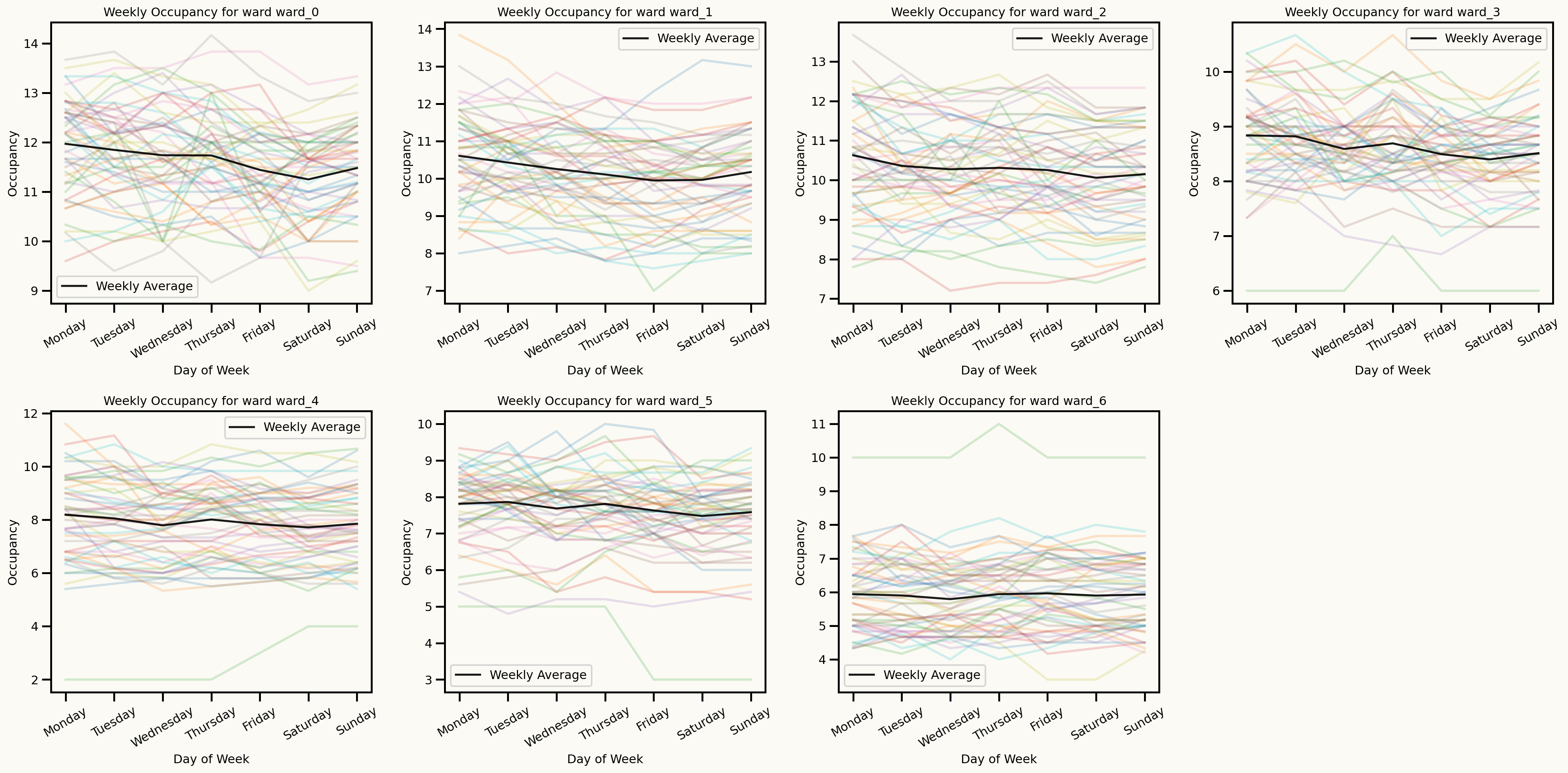
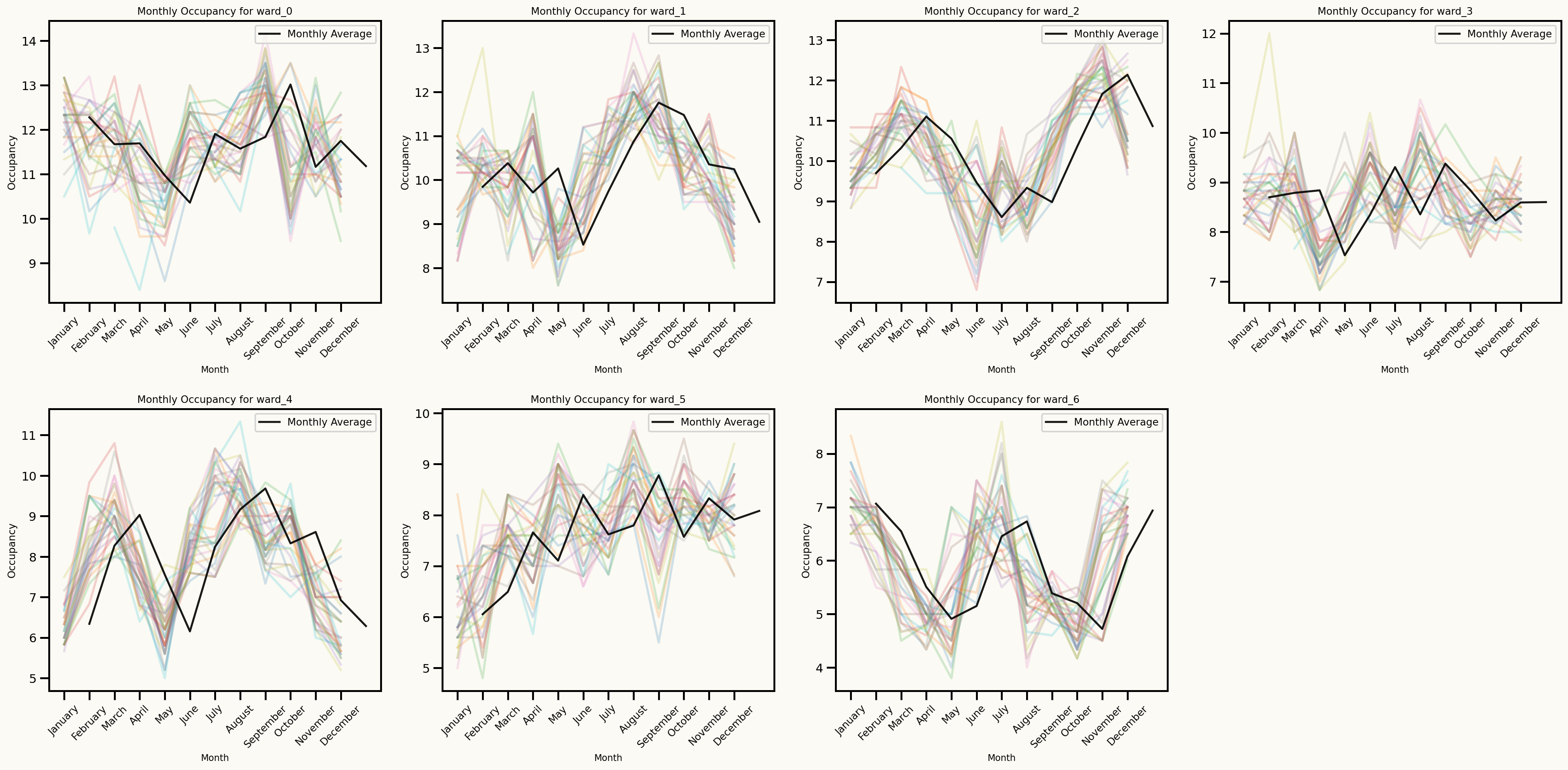
Seasonal patterns
Monthly seasonality
Effect of holidays
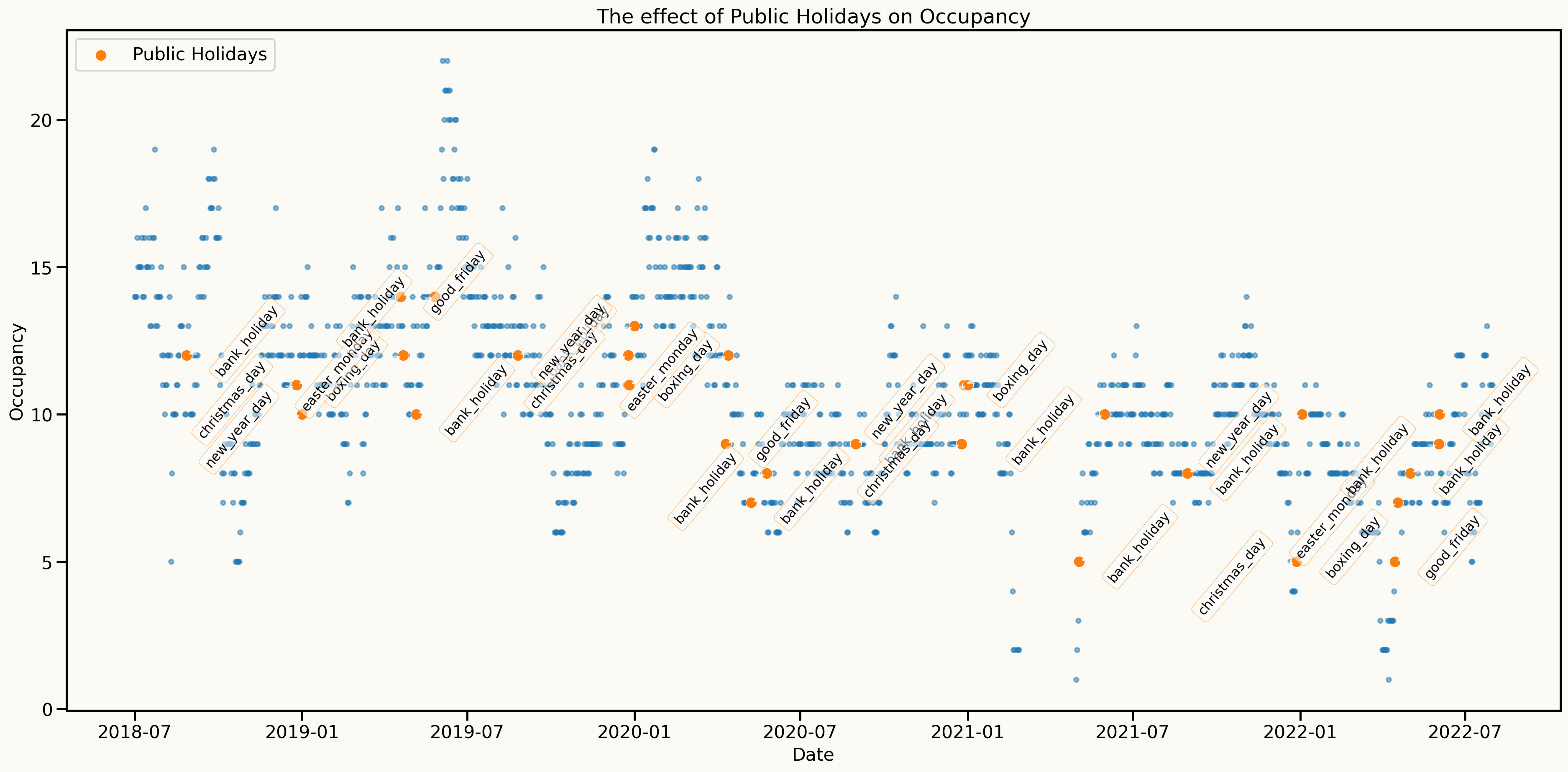
Key insights from data analysis
An important assumption to model: Stationarity
One approach to make the series stationary is to take the first difference of the series.
Original series: \(y_t, y_{t-1}, y_{t-2}, y_{t-3}, \ldots\)
Differenced series: \(y_t - y_{t-1}, y_{t-1} - y_{t-2}, y_{t-2} - y_{t-3}, \ldots\)
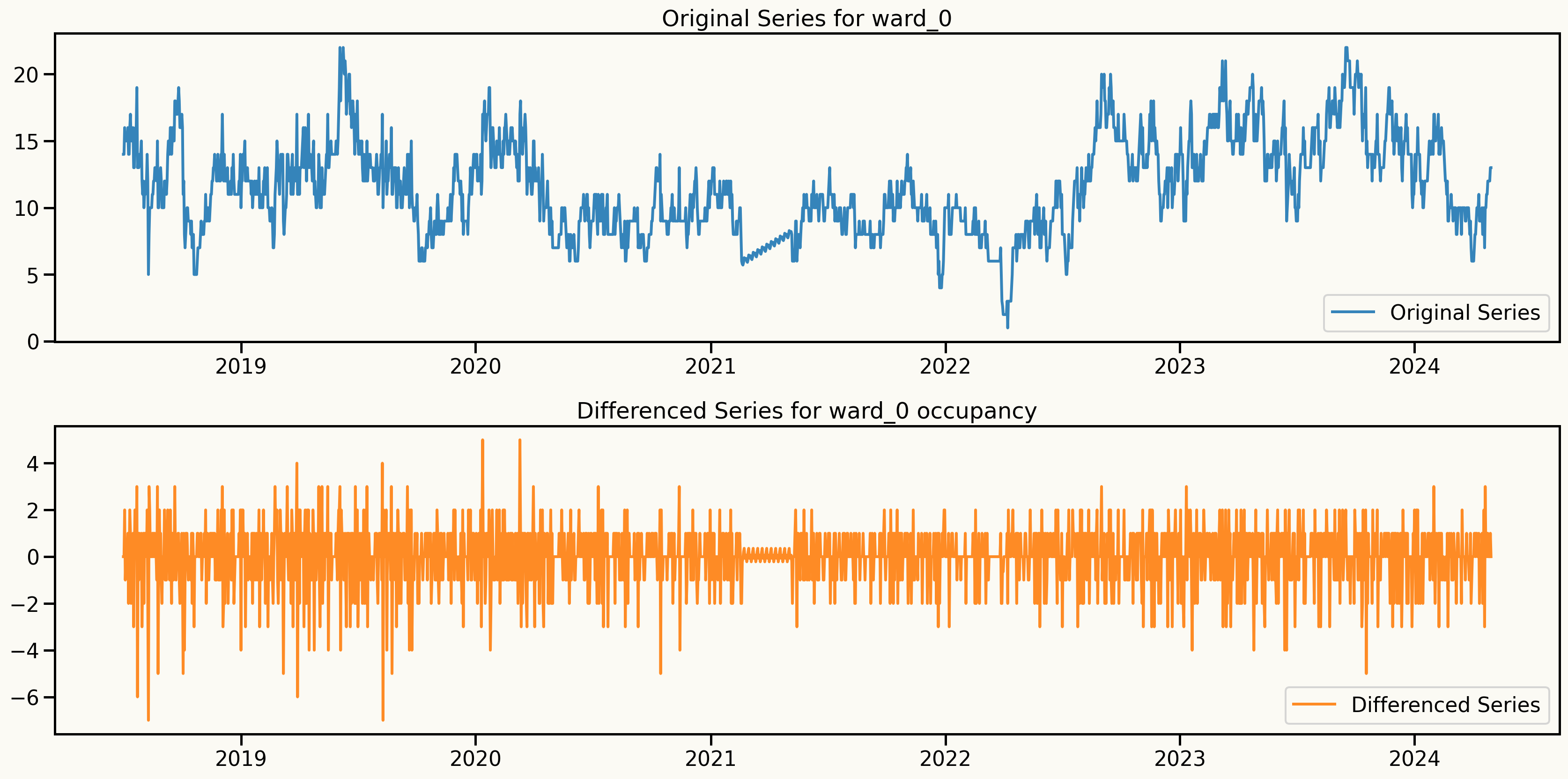
Key insights from data analysis
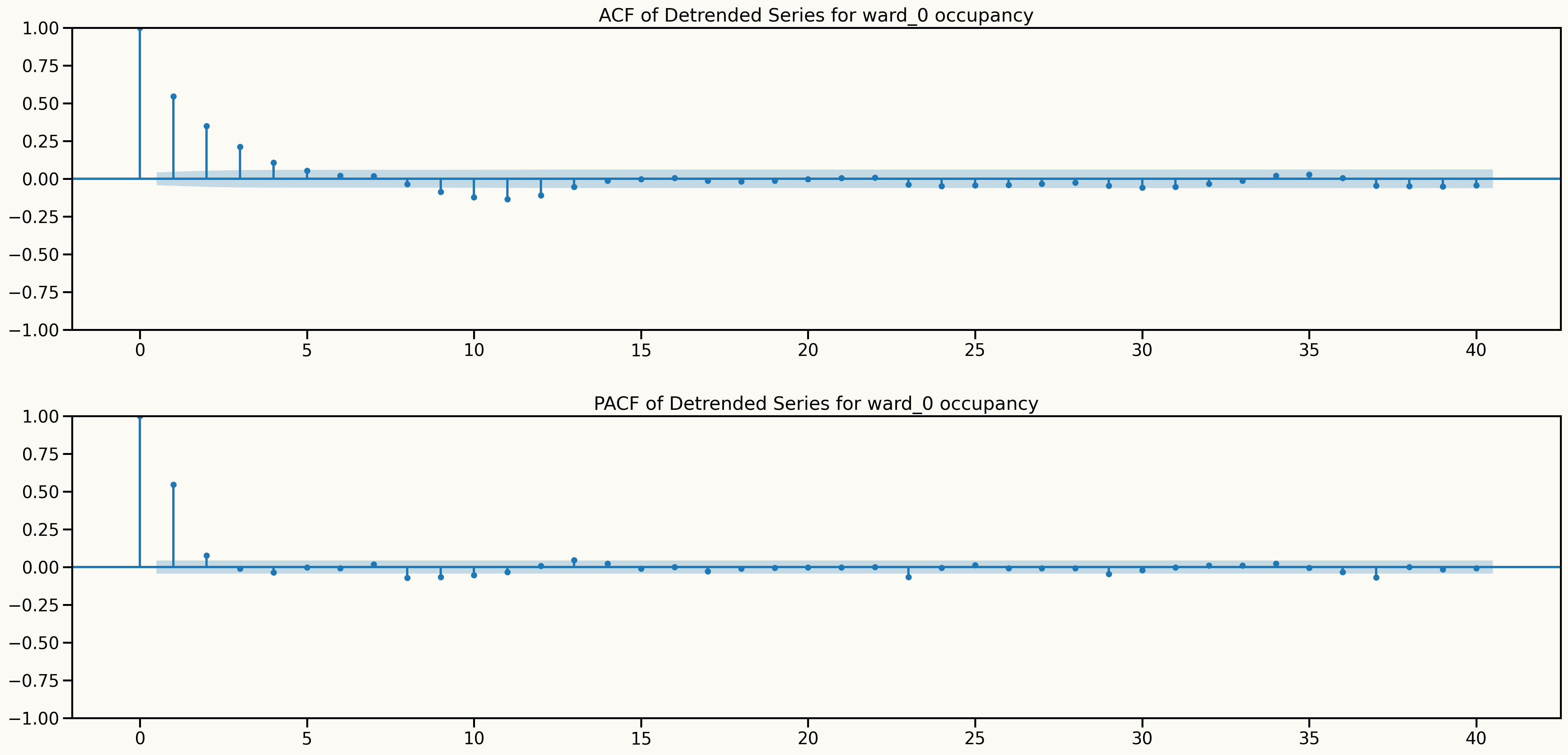
Information from ACF and PACF plots after differencing
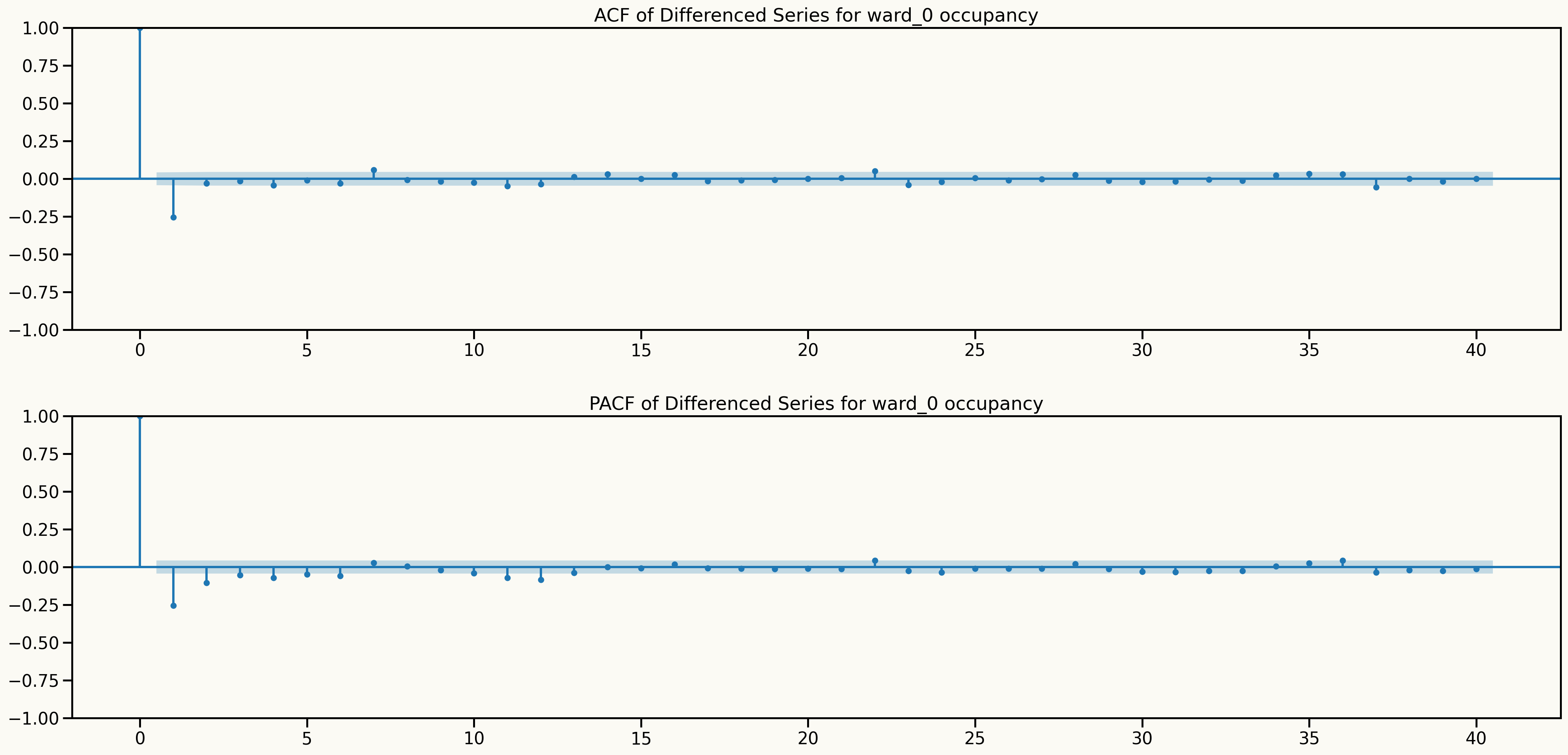
Key insights from data analysis
Alternative approach to make the series stationary and keep the dependence structure
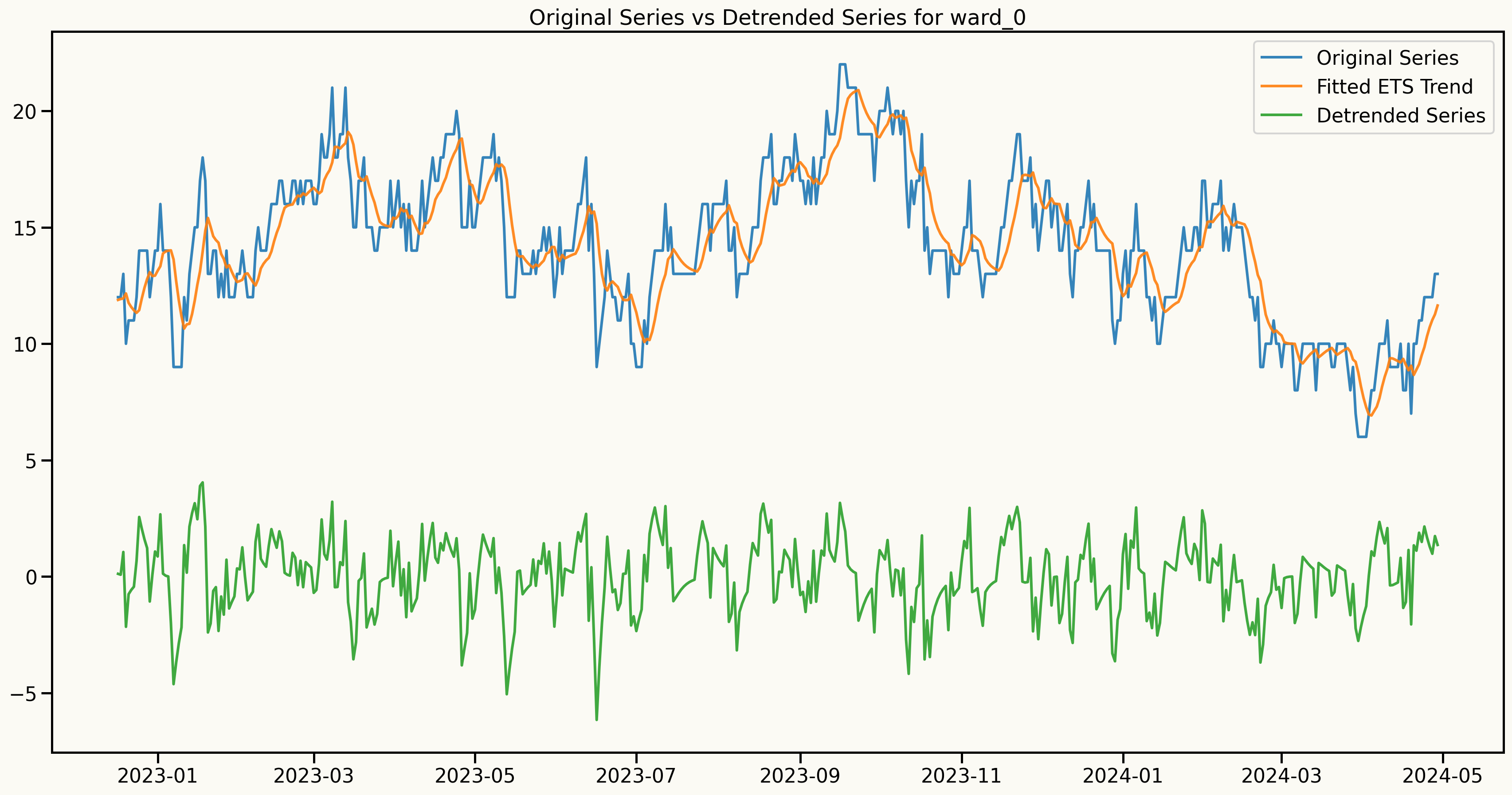
An important assumption to model: Stationarity
Information from ACF and PACF plots after detrending
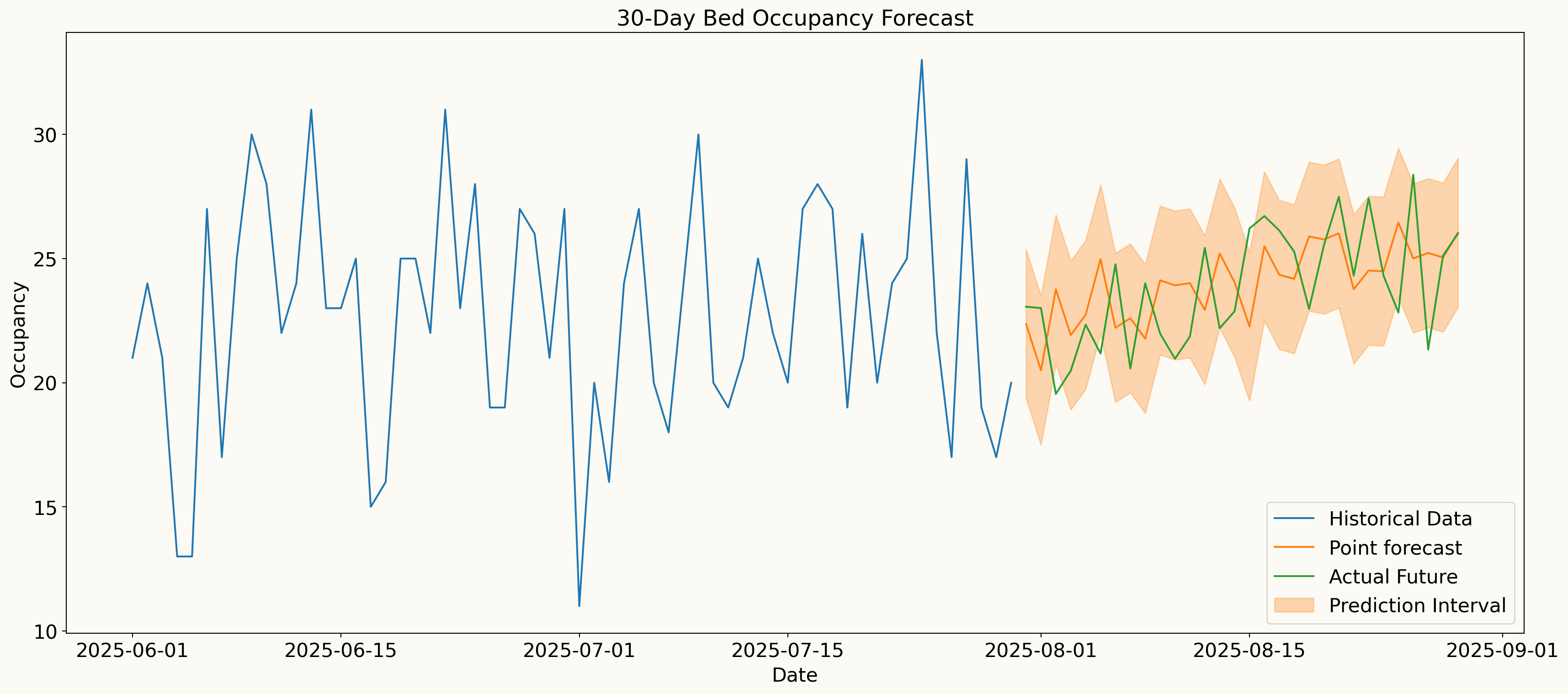
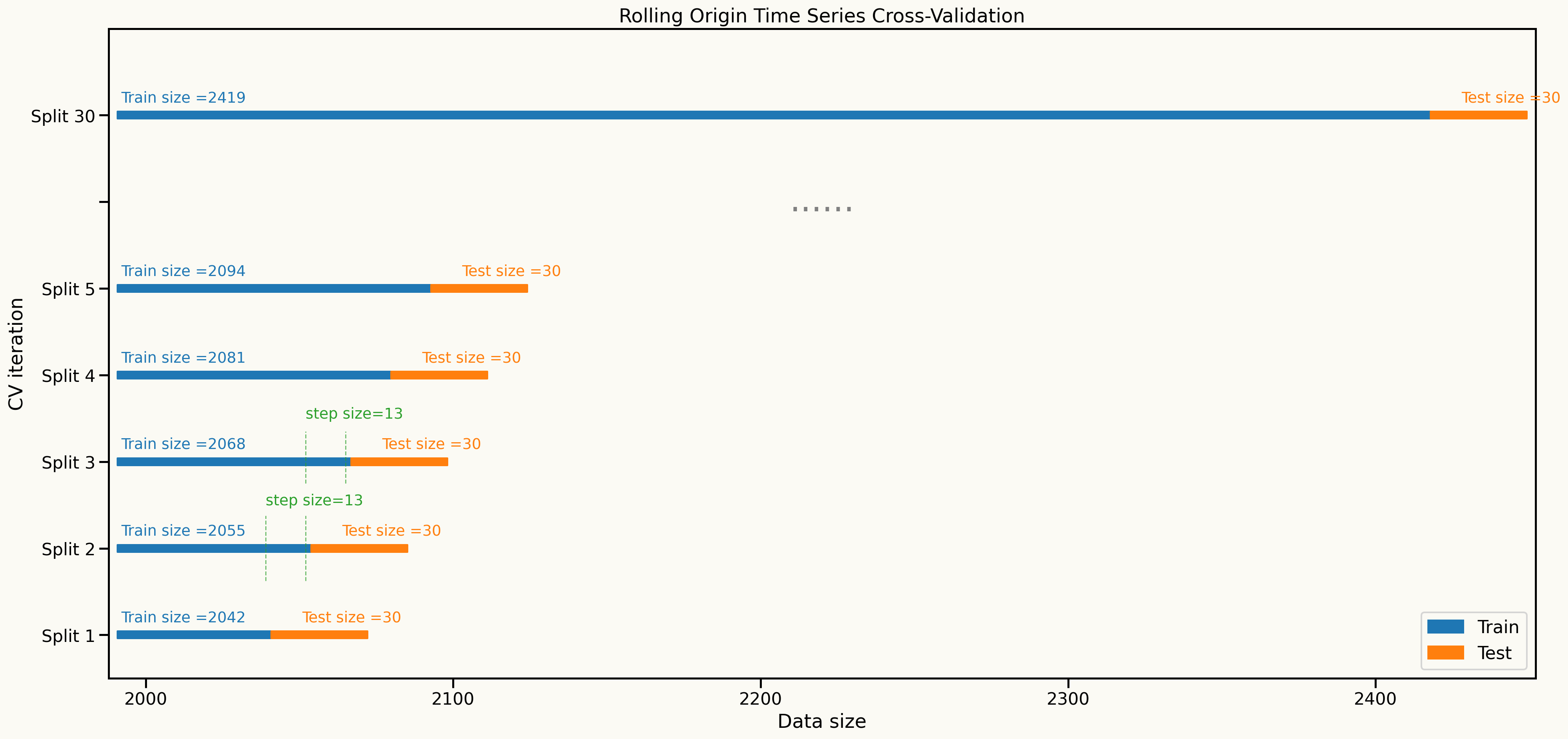
Cross validation setup
Rolling-origin cross-validation is used to evaluate model performance over time
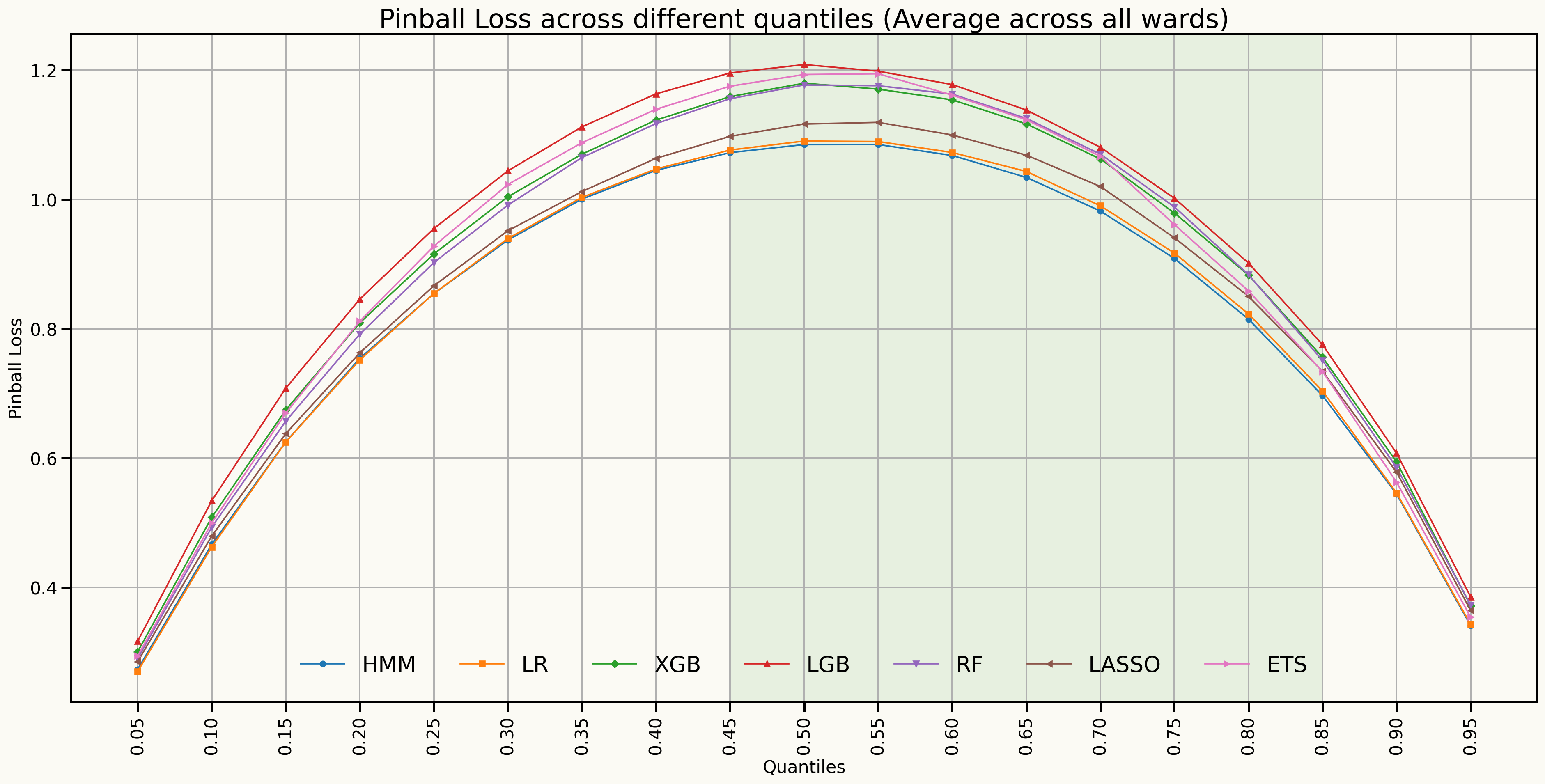
Forecast Distributions (Quantile scores)
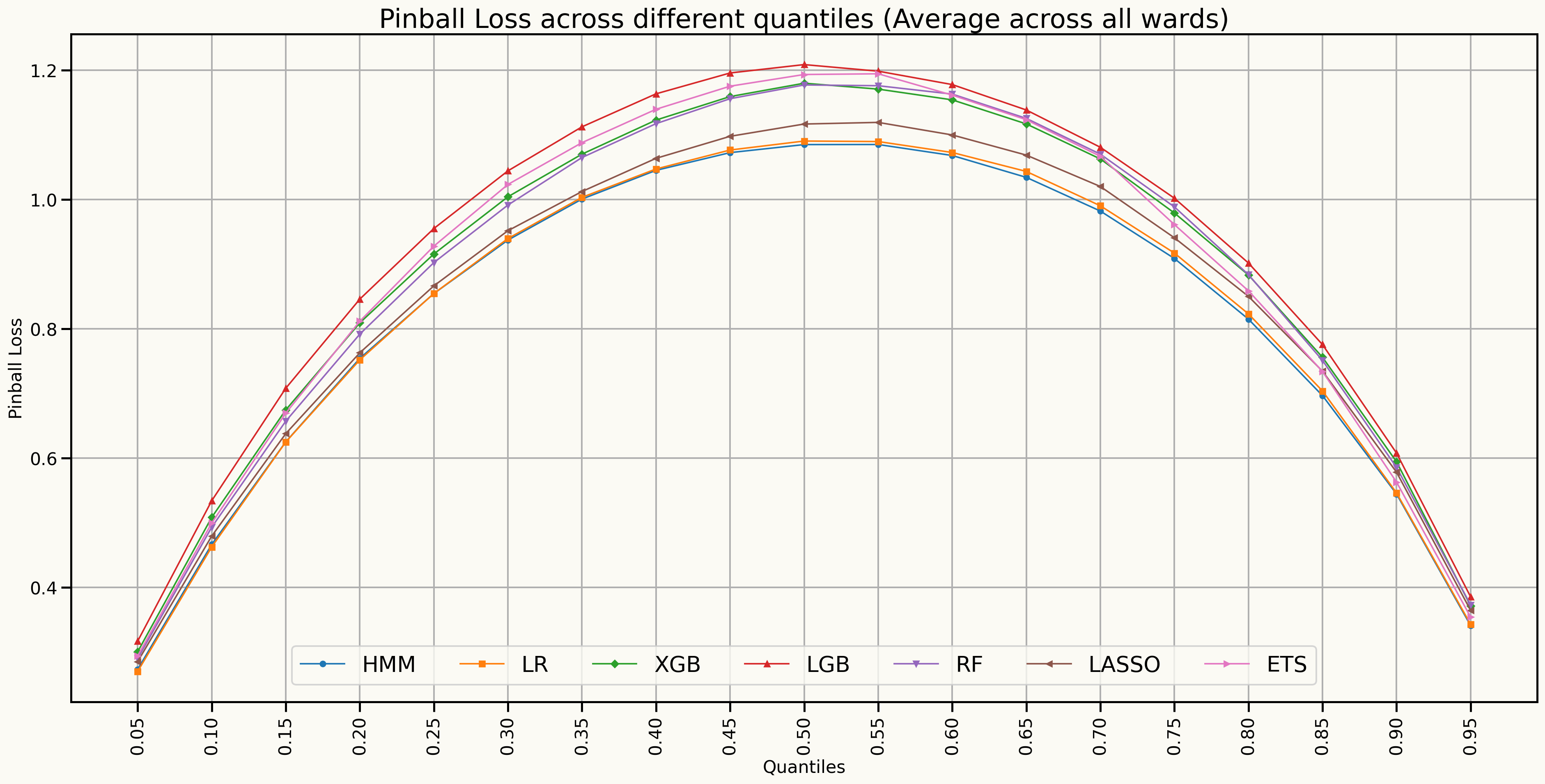
Forecast Distributions (Quantile scores)
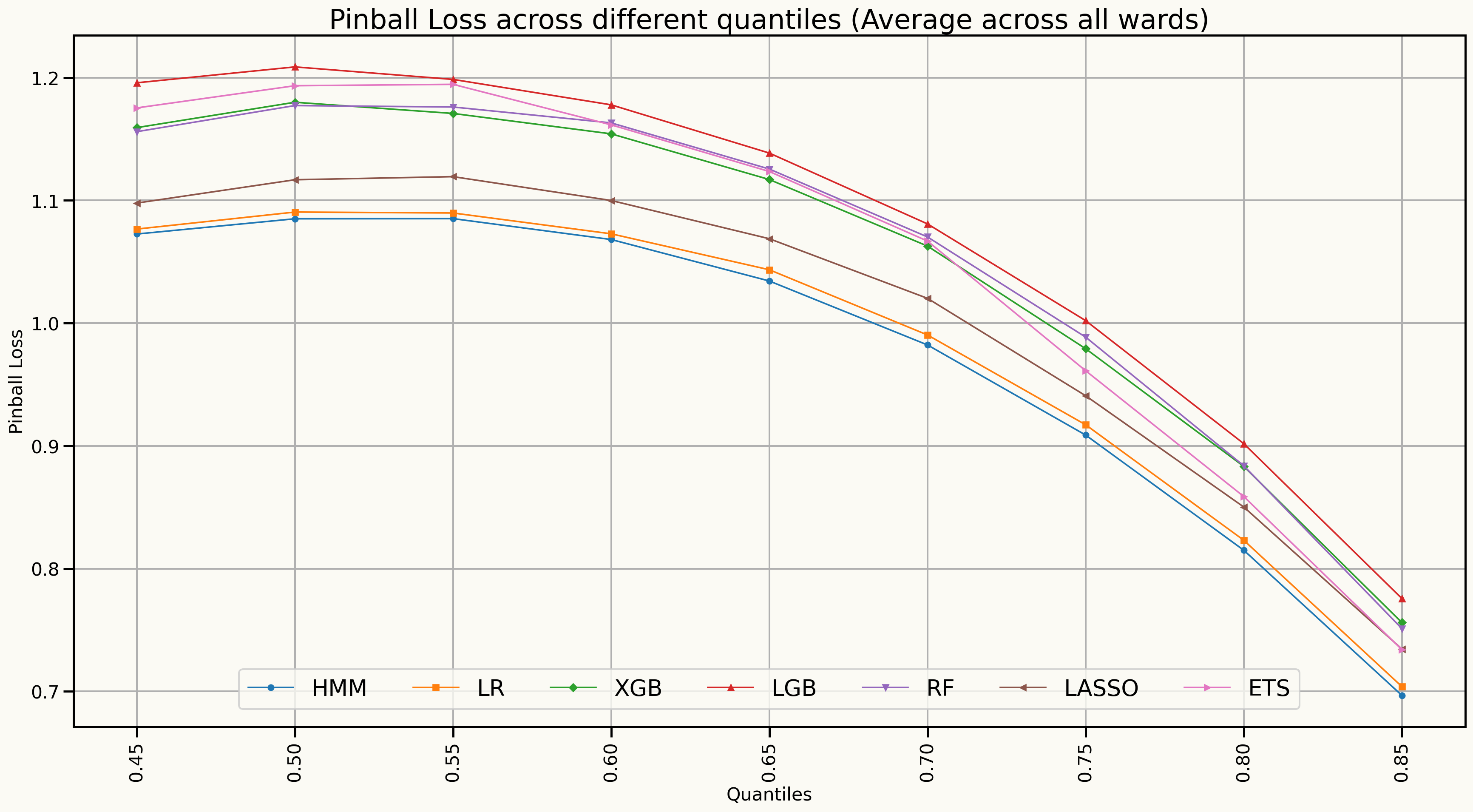
Forecast distributions (Quantile scores for 45% to 85%)
Model’s Explainability
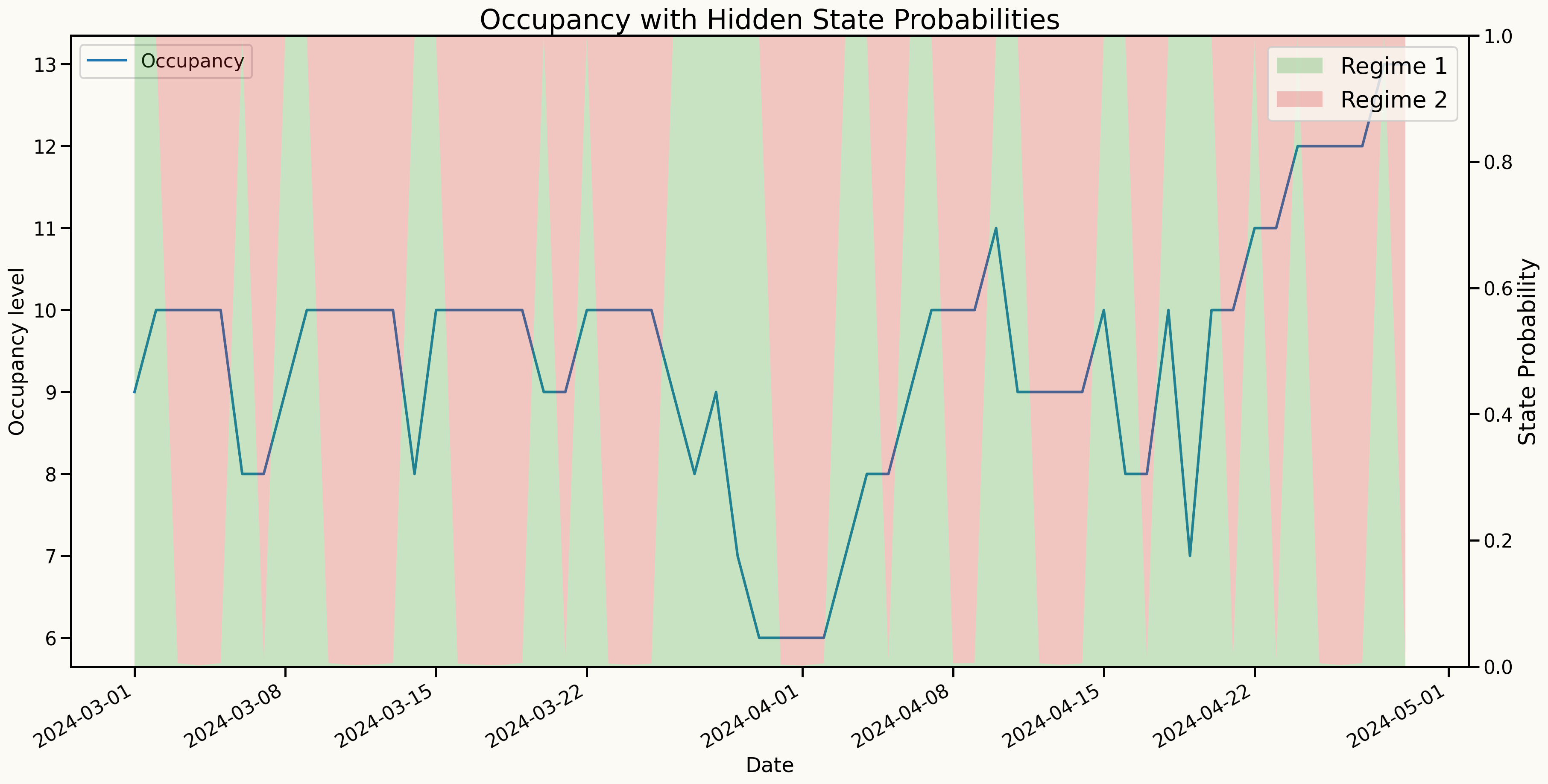
Transition probabilities
| T. Matrix | Regime 1 | Regime 2 |
|---|---|---|
| Regime 1 | 0.666 | 0.334 |
| Regime 2 | 0.487 | 0.513 |
Standard Deviations
| Std. Dev. | Regime 1 | Regime 2 |
|---|---|---|
| sd | 1.393 | 0.006 |
Any questions or thoughts? 💬
